03. Infraestrutura de Estatísticas de Uso LA Referencia
O sistema de estatísticas da LA Referencia opera em uma infraestrutura compartilhada na Amazon AWS, mantida como parte dos serviços fornecidos pela LA Referencia, graças às contribuições dos países membros e ao apoio da SCOSS.
A infraestrutura é baseada em um conjunto de componentes abertos publicados no GitHub como parte do compromisso de contribuir para o Ecossistema Global de Ciência Aberta.
- Componentes de banco de dados de fontes, administração e bibliotecas de normalização de identificadores
- Componentes de armazenamento e preservação de eventos
- Componentes de processamento, limpeza, normalização e agregação de eventos
- Componentes de serviços web para repositórios e agregadores
Acessando aqui, você poderá ver todo o código-fonte dos componentes
Componentes de banco de dados de fontes, administração e bibliotecas de normalização de identificadores
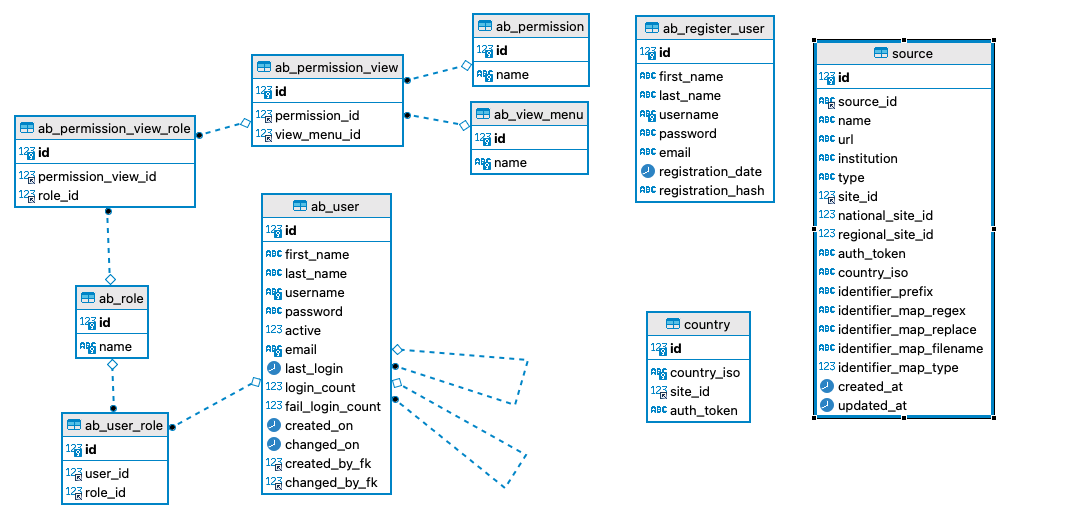
Banco de Dados do Serviço de Estatísticas de Uso
Acesso ao código e manuais de instalação
https://github.com/lareferencia/lareferencia-usage-stats-db
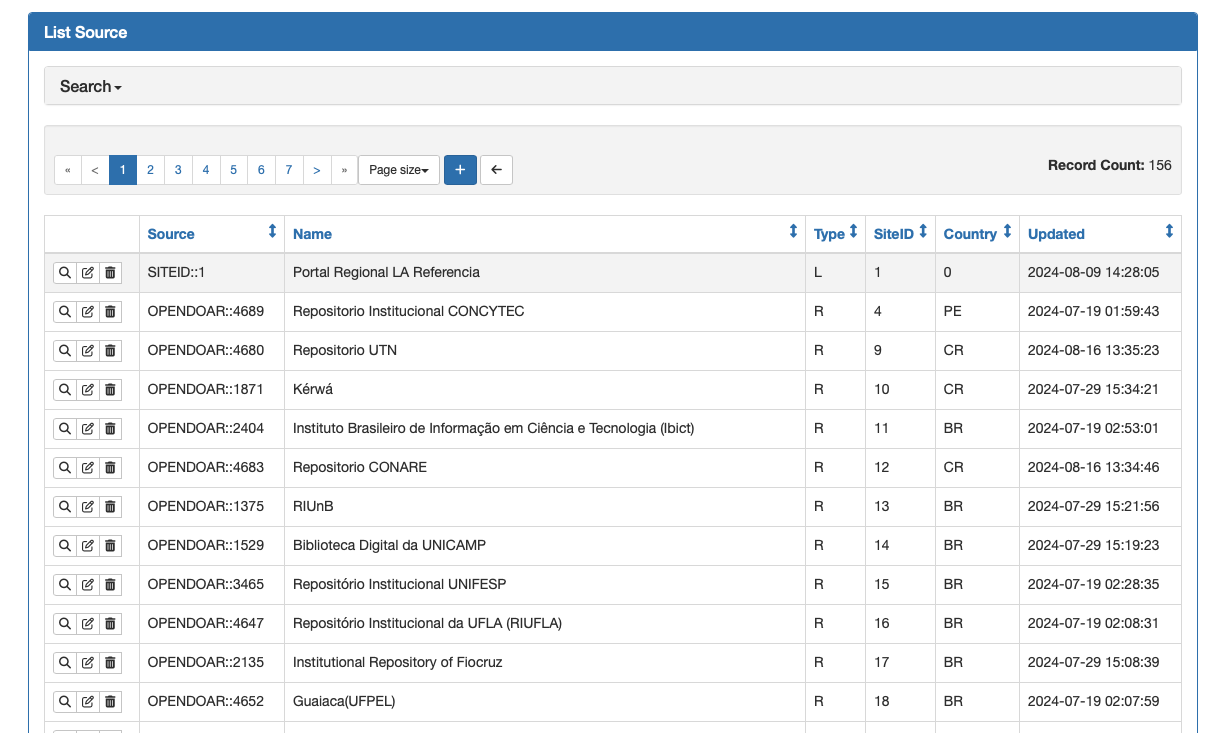
Sistema de Administração e Orquestração
Acesso ao código e manuais de instalação
https://github.com/lareferencia/lareferencia-usage-stats-admin
Componente de Armazenamento e Preservação de Eventos
Armazenamento AWS S3 e Matomo para S3
Acesso ao código e manuais de instalação
https://github.com/lareferencia/lareferencia-usage-stats-processor
Componente de Processamento, Limpeza, Normalização e Agregação de Eventos
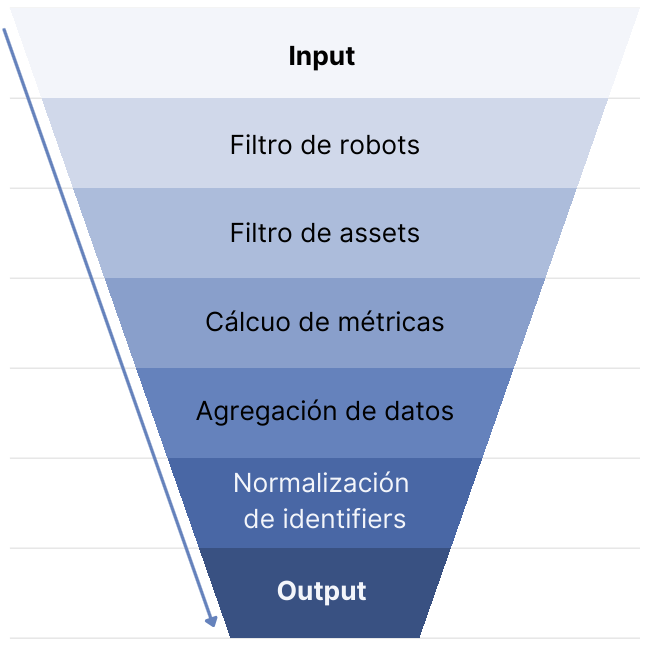
Software de processamento desenvolvido em Python com o objetivo de filtrar e normalizar as informações armazenadas no S3 Parquet, que depois são persistidas em índices Elastic/OpenSearch.
Carregamento de arquivos Parquet do Amazon S3
Essa etapa carrega arquivos Parquet de um repositório específico em uma data determinada. Durante esse processo, são extraídos os dados de sessão do usuário e os eventos associados a essa sessão.
Filtro de robôs
O propósito dessa etapa é melhorar a confiabilidade dos dados estatísticos. O filtro permite identificar e eliminar as sessões e eventos gerados por robôs, garantindo que apenas dados autênticos sejam analisados.
Filtro de assets
Semelhante à etapa anterior, esta fase continua a melhorar a qualidade dos dados estatísticos. Aqui, eventos errôneos, como os “downloads” de miniaturas (thumbnails), são detectados e eliminados quando o coletor de estatísticas registra incorretamente a visualização de uma miniatura como um download.
Cálculo de métricas
Nesta etapa, são calculadas as visualizações, downloads e links associados a uma sessão específica e seu identificador. Além disso, uma nova métrica chamada “conversões” é introduzida, baseada em combinações de visualizações com downloads ou visualizações com links.
Agregação de dados
Esta fase agrega dados por item (identificador), calculando as visualizações, downloads, links e conversões de um item, independentemente das sessões que o consultaram. Esses dados também são agregados por país de origem do evento.
Normalização de identificadores
O objetivo desta etapa é homogenizar e padronizar os identificadores (identifiers) provenientes dos repositórios, melhorando a consistência dos dados.
Indexação no ElasticSearch/OpenSearch
Nesta etapa final, são feitos os últimos ajustes no fluxo de dados para garantir uma indexação eficaz e eficiente no OpenSearch ou ElasticSearch.
Pipeline S3 para Elastic/OpenSearch
Acesso ao código e manuais de instalação
https://github.com/lareferencia/lareferencia-usage-stats-processor
Componente de Serviços Web para Repositórios e Agregadores

Serviços Web de Estatísticas de Uso
Acesso ao código e manuais de instalação
https://github.com/lareferencia/lareferencia-usage-services