03. LA Referencia Usage Statistics Infrastructure
The LA Referencia statistics system operates on a shared infrastructure in Amazon AWS, maintained as part of the services provided by LA Referencia thanks to contributions from member countries and SCOSS support.
The infrastructure is based on a set of open components published on GitHub as part of the commitment to contribute to the Global Open Science Ecosystem.
- Database, management, and identifier normalization libraries components
- Storage and event preservation components
- Processing, cleaning, normalization, and event aggregation components
- Web services components for repositories and aggregators
By clicking here, you can access all the source code for the components
Database, management, and identifier normalization libraries components
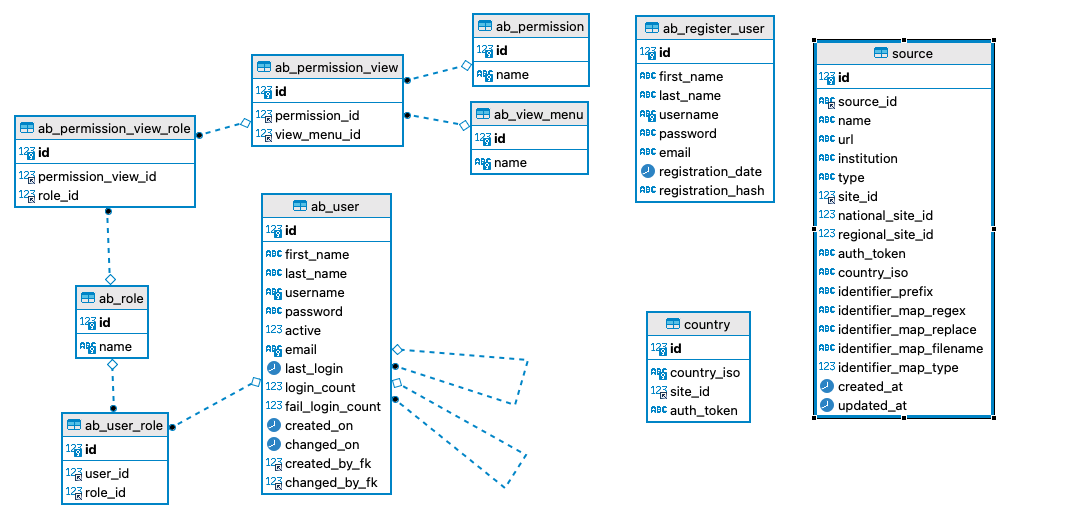
Usage Statistics Service DB
Access to code and installation manuals
https://github.com/lareferencia/lareferencia-usage-stats-db
Administration and Orchestration System
Access to code and installation manuals
https://github.com/lareferencia/lareferencia-usage-stats-admin
Storage and event preservation component
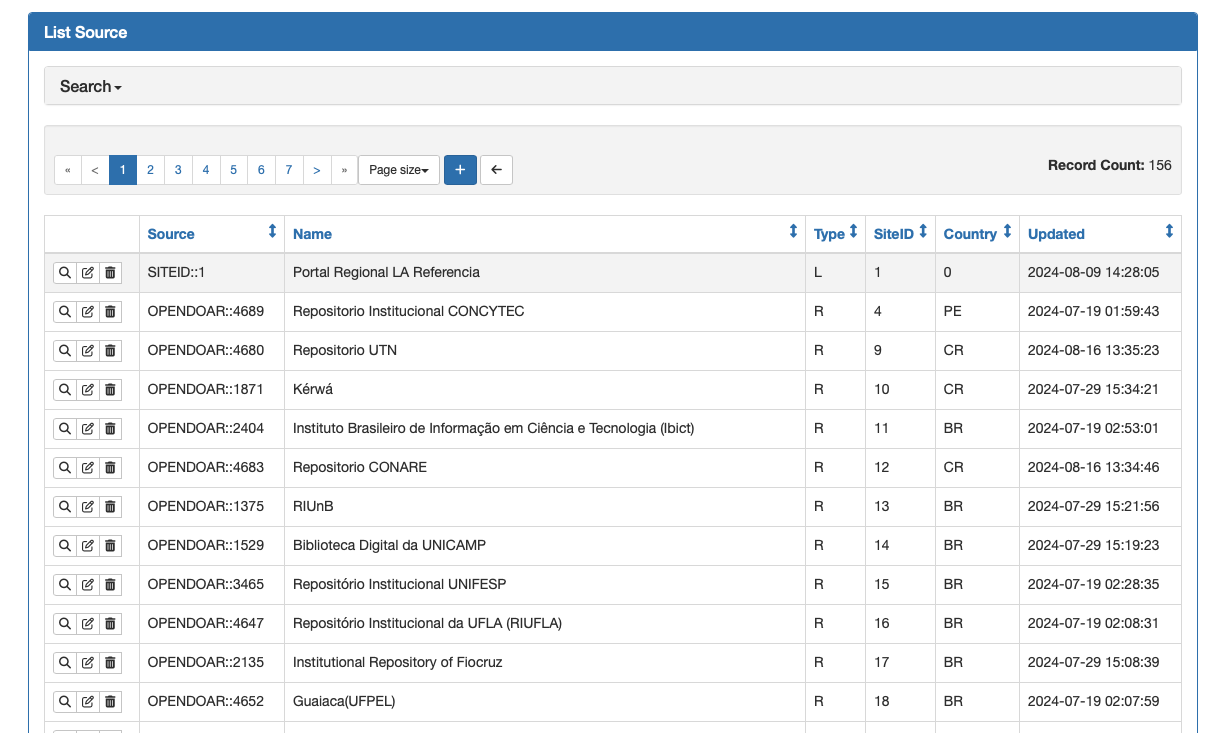
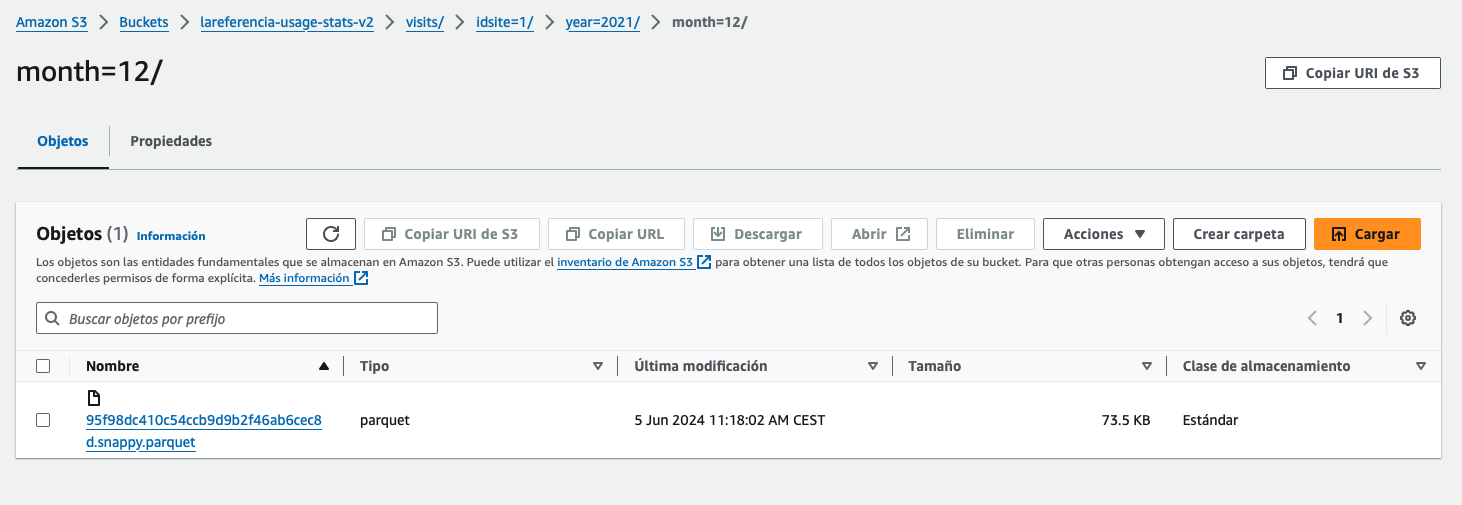
AWS S3 Storage and Matomo to S3
Access to code and installation manuals
https://github.com/lareferencia/lareferencia-usage-stats-processor
Processing, cleaning, normalization, and event aggregation component
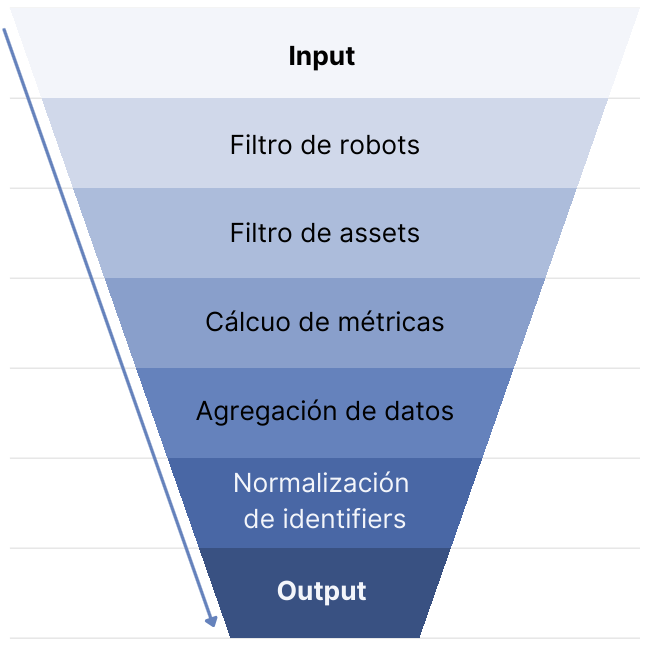
Processing software developed in Python, aimed at filtering and normalizing the information stored in S3 Parquet, which is later persisted in Elastic/OpenSearch indices.
Loading Parquet files from Amazon S3
This step loads Parquet files from a specific repository on a given date. During this process, user session data and associated events are extracted.
Bot filtering
The purpose of this step is to improve the reliability of the statistical data. The filter allows the identification and removal of sessions and events generated by bots, ensuring that only authentic data is analyzed.
Asset filtering
Similar to the previous step, this phase seeks to further enhance the quality of statistical data. Here, erroneous events like “thumbnail downloads” are detected and removed, when the statistics collector incorrectly registers a thumbnail view as a download.
Metric calculation
In this step, visits, downloads, and links associated with a specific session and its identifier (identifier) are calculated. Additionally, a new metric called “conversions” is introduced, which is based on combinations of views with downloads or views with links.
Data aggregation
This phase aggregates data by item (identifier), calculating views, downloads, links, and conversions of an item, regardless of the sessions that accessed it. These data are also aggregated by the country of origin of the event.
Identifier normalization
The goal of this step is to homogenize and standardize the identifiers (identifiers) from repositories, improving data consistency.
ElasticSearch/OpenSearch indexing
In this final step, the last adjustments in the data flow are made to ensure effective and efficient indexing in OpenSearch or ElasticSearch.
S3 to Elastic/OpenSearch Pipeline
Access to code and installation manuals
https://github.com/lareferencia/lareferencia-usage-stats-processor
Web services components for repositories and aggregators

Usage Statistics Web Services
Access to code and installation manuals
https://github.com/lareferencia/lareferencia-usage-services