03. Infraestructura de Estadísticas de Uso LA Referencia
El sistema de estadísticas LA Referencia funciona en una infraestructura común en Amazon AWS, mantenida como parte de los servicios que LA Referencia brinda gracias a los aportes de los países miembro y los aportes SCOSS.
La infraestructura está basada en un conjunto de componentes abiertos publicados en Github como parte del compromiso de contribuir al Ecosistema Global de Ciencia Abierta.
- Componentes de base de datos de fuentes, administración y librerías de normalización
- Componentes de almacenamiento y preservación de eventos
- Componentes de procesamiento, limpieza, normalización y agregación de eventos
- Componentes de servicios web para repositorios y agregadores
Ingresando aquí podrá acceder a todo el código fuente de los componentes
Componentes de base de datos de fuentes, administración y librerías de normalización
Usage Statitics Service DB
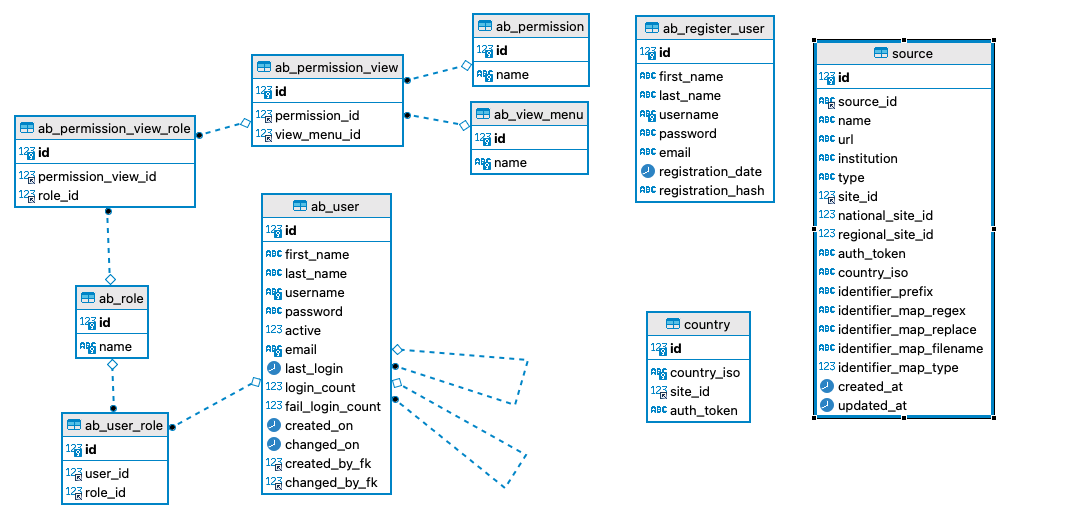
Acceso al código y manuales de instalación
https://github.com/lareferencia/lareferencia-usage-stats-db
Sistema de administración y orquestación
Acceso al código y manuales de instalación
https://github.com/lareferencia/lareferencia-usage-stats-admin
Componente de almacenamieno y preservación de eventos
AWS S3 Storage y Matomo to S3
Acceso al código y manuales de instalación
https://github.com/lareferencia/lareferencia-usage-stats-processor
Componente de procesamiento, limpieza, normalización y agregación de eventos
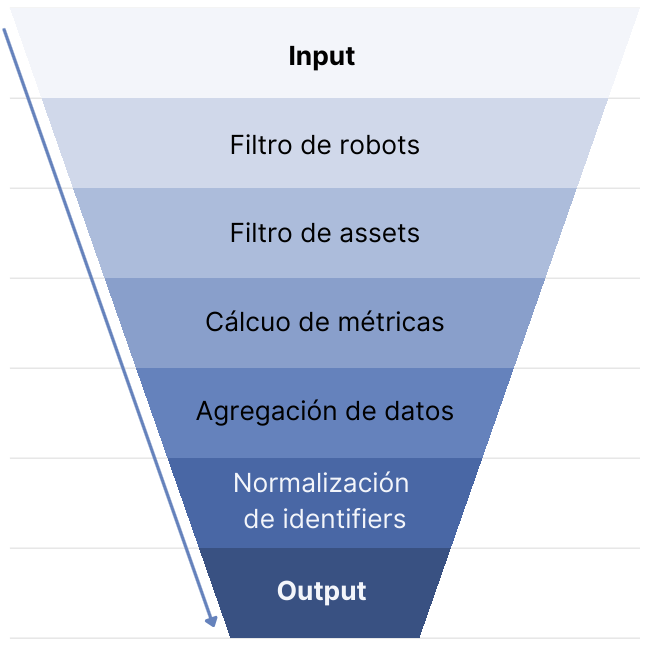
Software de procesamiento desarrollado en Python con el objetivo de filtrar y normalizar la información almacenada en S3 Parquet que luego es persitida en índices Elastic/OpenSearch
Carga de archivos Parquet desde Amazon S3
Esta etapa se encarga de cargar archivos Parquet desde un repositorio específico en una fecha determinada. Durante este proceso, se extraen los datos de sesión del usuario y los eventos asociados a esa sesión.
Filtro de robots
El propósito de esta etapa es mejorar la fiabilidad de los datos estadísticos. El filtro permite identificar y eliminar las sesiones y eventos generados por robots, asegurando que solo se analicen datos auténticos.
Filtro de assets
Similar a la etapa anterior, esta fase busca continuar mejorando la calidad de los datos estadísticos. Aquí se detectan y eliminan eventos erróneos, como las “descargas” de miniaturas (thumbnails), cuando el recolector de estadísticas registra de manera incorrecta la visualización de una miniatura como una descarga.
Cálculo de métricas
En esta etapa, se calculan las visitas, descargas y enlaces asociados a una sesión específica y su identificador (identifier). Además, se introduce una nueva métrica llamada “conversiones”, que se basa en combinaciones de vistas con descargas o vistas con enlaces.
Agregación de datos
Esta fase realiza la agregación de datos por ítem (identifier), calculando las vistas, descargas, enlaces y conversiones de un ítem, independientemente de las sesiones que lo consultaron. También se agregan estos datos segmentados por el país de origen del evento.
Normalización de identificadores
El objetivo de esta etapa es homogeneizar y estandarizar los identificadores (identifiers) provenientes de los repositorios, mejorando la consistencia de los datos.
Indexación en ElasticSearch/OpenSearch
En esta etapa final, se realizan los últimos ajustes en el flujo de datos para asegurar una indexación eficaz y eficiente en OpenSearch o ElasticSearch.
S3 to Elastic/OpenSearch Pipeline
Acceso al código y manuales de instalación
https://github.com/lareferencia/lareferencia-usage-stats-processor
Componente de servicios web para repositorios y agregadores

Usage Statitics Web Services
Acceso al código y manuales de instalación
https://github.com/lareferencia/lareferencia-usage-services